
In navigating the dynamic terrain of evolving technology to leverage the potential of data, it is imperative to establish a well-defined dataflow and architecture. Microsoft Fabric simplifies the process of constructing both straightforward and highly potent Data Lakehouse solutions. The primary objectives of a Data Lakehouse Architecture include:
- Establishing a unified data platform
- Ensuring scalability and flexibility
- Enhancing performance while remaining cost-effective
- Eliminating data silos
- Facilitating improved decision-making
- Boosting operational efficiency
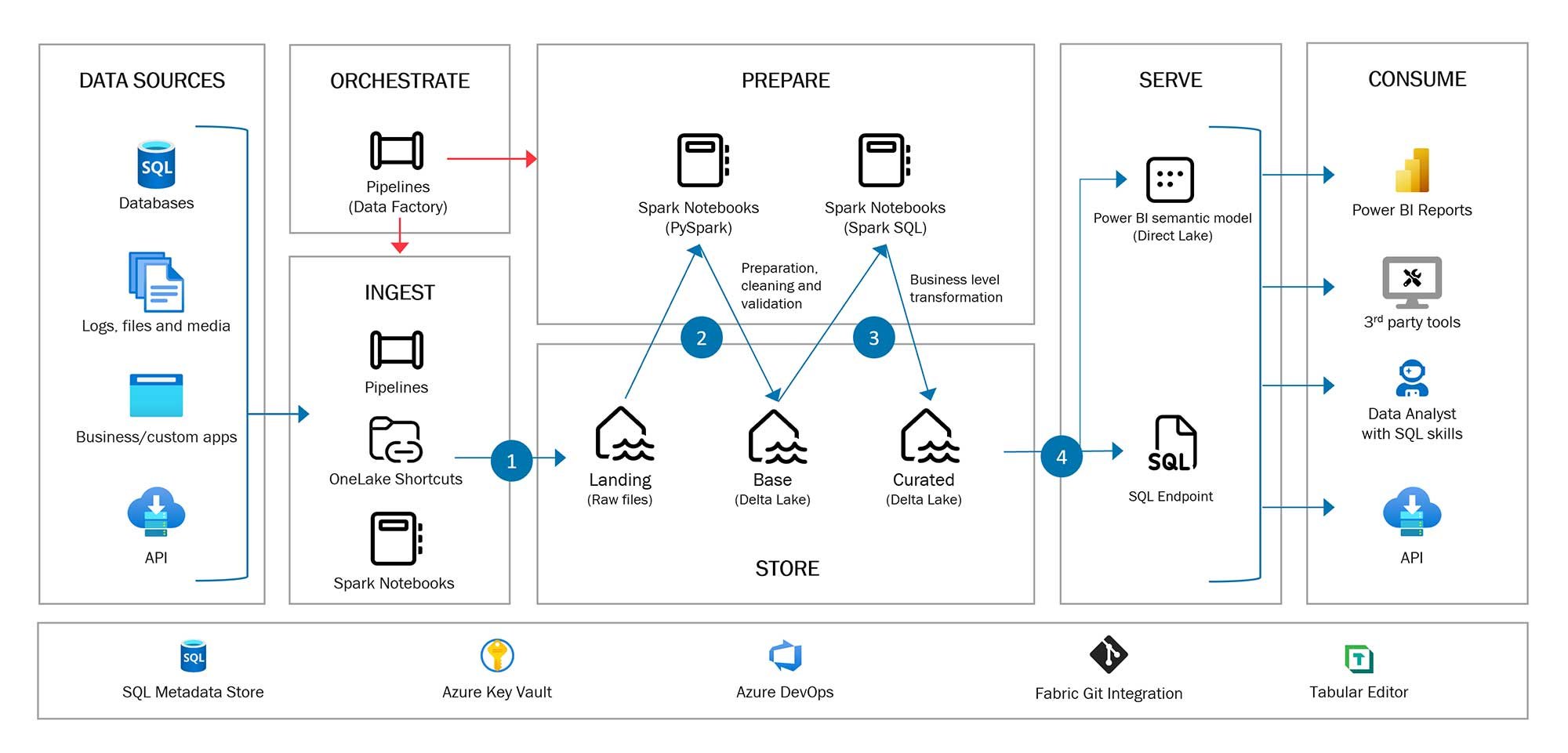
Fig 1: Microsoft Fabric Best Practice Architecture
Essential Phases in a Data Lakehouse
In the core of a Data Lakehouse, a sequence of four key phases unfolds: Ingest, Store, Prepare, and Serve—a classic ETL process. These phases act like the gears of a well-coordinated machine, smoothly guiding data through the system from its sources to end consumers.
Step 1: Ingesting raw data from sources
Raw data from diverse sources is initially ingested into the "Landing" section of the Lakehouse. This crucial step is efficiently facilitated by the reliable Data Factory Pipelines, ensuring seamless data entry. OneLake provides shortcuts for both external and internal data sources, and Spark notebooks excel at handling data from APIs, among other sources. Additionally, Fabric introduces Real-Time Analytics, contributing a dynamic ingestion mechanism to the toolkit.
Step 2: Metadata-driven Preparation and Cleaning
Data undergoes preparation, cleaning, and validation processes, where one or more metadata-driven notebooks, with PySpark being a preferred choice, come into play. The cleansed data is then stored in the Delta Lake format within the "Base" Lakehouse item, ensuring data integrity and reliability.
Step 3: Spark SQL-Powered Business Transformations
Post-cleaning, the data moves to business-level transformations. Here, data is transformed into dimensions and facts to enhance its meaning and insight. Like the preparation phase, one or more notebooks, primarily utilizing Spark SQL, perform these tasks. The transformed data is saved once again in the Delta Lake format, this time within a Lakehouse item named "Curated."
Step 4: Serving Insights to End Consumers
The ultimate objective of any data platform is to deliver valuable insights to all end users of the solution. In the Data Lakehouse, this is achieved through a Power BI Semantic model in Direct Lake mode. Alternatively, the SQL Endpoint provides a more traditional means of making data accessible to consumers.
Orchestrating a Seamless Dataflow
To maintain synchronization and ensure a seamless dataflow, Data Factory Pipelines play a crucial role as orchestrators. They manage the movement of data through different phases and handle dependencies within these phases.
Conclusion
The architecture and dataflow within a Data Lakehouse, powered by Microsoft Fabric, present a potent and adaptable solution for managing data at scale. By comprehending the essential components and processes involved, organizations can unlock the full potential of their data, fostering informed decision-making and innovation.
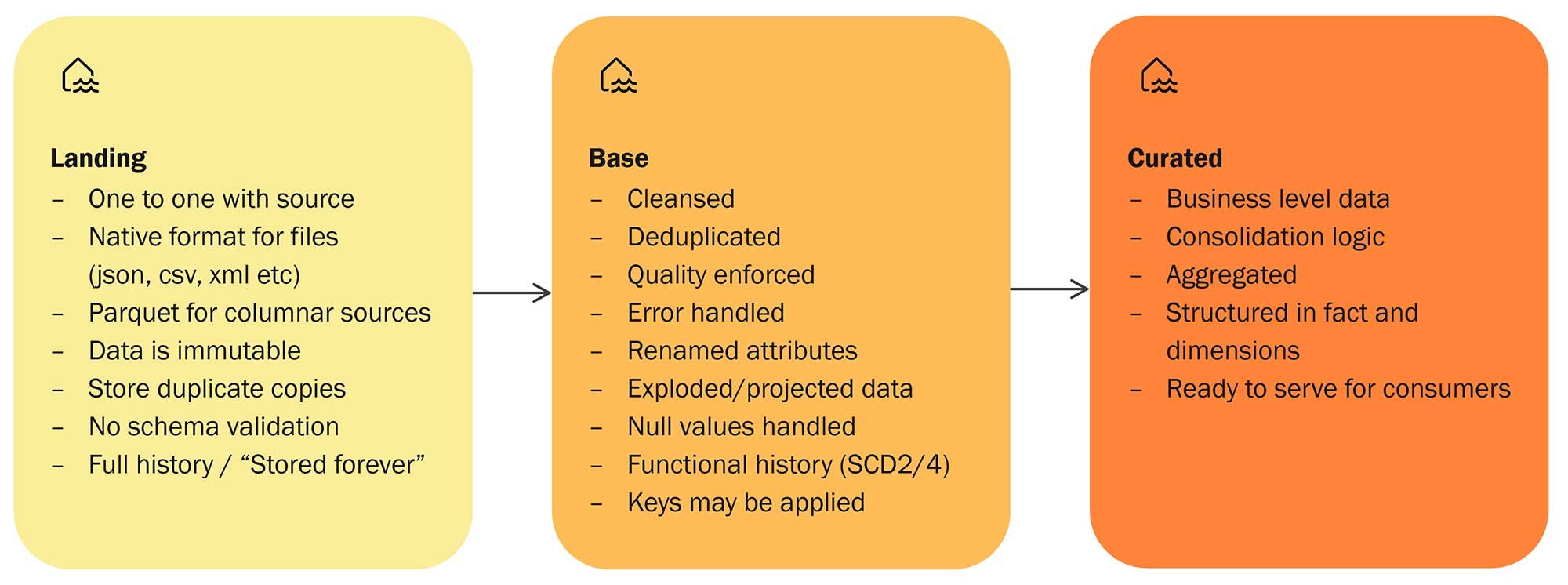
Fig 2: Layers in the Data Lakehouse
Elevating the architecture with a comprehensive framework
A Best Practice Framework (BPF) serves as a robust toolset, streamlining the swift creation and maintenance of Data Lakehouse solutions. By employing a framework, mundane aspects of Data Lakehouse and infrastructure development can be automatically generated, freeing developers to concentrate on the core business logic. This approach significantly enhances both productivity and development quality.
Constructed with the principles of convention over configuration, the framework utilizes templates, established standards, and comprehensive documentation covering everything from data lakehouse setup and configuration to data extraction and modeling. The Best Practice Framework establishes a strong foundation for ongoing development, ensuring a favorable starting point.
Key advantages of a Data Lakehouse Best Practice Framework:
- Layered Architecture: Simplifies the central definition, configuration, and automation of the dataflow.
- Extendable: Allows for seamless integration of new methods and logic.
- Faster Time-to-Market: Significantly reduces development time by addressing routine tasks, enabling developers to focus on value-driven activities for the business.
- Maintenance through Metadata: Leverages metadata for configuration, minimizing the need for labor-intensive manual processes.
- DevOps Ready: Out of the box, the BPF seamlessly integrates with Azure DevOps, covering the entire spectrum from initial setup and development to infrastructure and deployment.
This framework introduces additional components to the architecture:
- Azure SQL Database: Acts as a metadata store for dynamic ingest pipelines and automates data preparation, cleaning, and validation. This allows for the creation of generic Pipelines and Spark notebooks.
- Azure Key Vault: Safely stores sensitive information such as connection strings, passwords, and credentials for source systems.
- Azure DevOps: Serves as a collaborative platform for task management, version control, documentation, CI/CD, and deployment.
- Fabric Git Integration: Connects the development workspace to a feature Git branch in Azure DevOps, ensuring straightforward version control and collaboration.
- Tabular Editor: Developing tool to generate one or more semantic models on top of the Data Lakehouse based on the structure and metadata, enhancing efficiency in model creation.

Fig 3: Framework components
The foundation of the Lakehouse Best Practice framework rests on architectural choices rooted in extensive experience with developing data platform solutions. It incorporates deep expert insight into the underlying Microsoft Fabric technology stack. A core design principle emphasizes the use of Fabric items whenever feasible, with the recommendation to resort to other services (Azure services) only when a Fabric version is not available.