
AI solutions are often evaluated based on their ability to make accurate predictions with new data, whether it is used to predict customers who are leaving a business or canceling their subscription, or sales figures for the next quarter. With the rapid development of AI and machine learning in recent years, which has led to new opportunities for automating important decision-making processes, there has been an increased focus on what is often referred to as 'explainable AI' or 'XAI.'
Why does the model says what it does?
The concept of explainable AI is defined differently depending on who you ask. For us, it is simply about:
-
Using methods to explain the output of AI/machine learning models
-
Extracting insights about the models and the data that goes into model training
-
Creating transparency and trust in decisions with AI components
By being able to explain what an AI solution actually does, you can get out of the "black box" and create transparency and trust among business users, as well as valuable knowledge that they can act on.
In the development phase, explainable AI methods help model developers better understand the business and the problem that needs to be solved. This knowledge is often quite useful and can help developers build better models. Afterwards, explainable AI can help business users understand a model's output and the impact that various input variables have on its predictions. Many AI solutions are "black box" models, where you really don't know what happens between input and output. But it doesn't necessarily have to be that way. Today, it has become much easier to scrutinize many types of models to get answers to important business questions. In the following sections, we will take a closer look at what explainable AI means and what types of information can be extracted from AI/ML models.
When data is gold - the importance of individual variables
Both for model development and communication of insights, it is usually essential to be able to examine the most valuable data in more detail. There are different methods for extracting so-called 'feature importances' depending on the model type. What they all have in common is that they seek to illustrate how much each input variable contributes to the model's output - in other words, how much predictive value the different variables have. This knowledge enables a more targeted processing of data and further development of models in an iterative process. At the same time, it provides the business user with a simple overview and knowledge of which information is most important for the model's output. The importance of the variables thus tells us where the "gold is hidden", but with a significant limitation; based on this alone, one cannot say how a given variable value affects a model's predictions. For example, calculating the importance of variables may reveal that age and tenure are important factors in predicting member churn in a subscription business, but not how much the probability of losing a member is affected by age and tenure. At the same time, variable importance does not tell us whether the probability increases or decreases as a member's age or tenure increases.
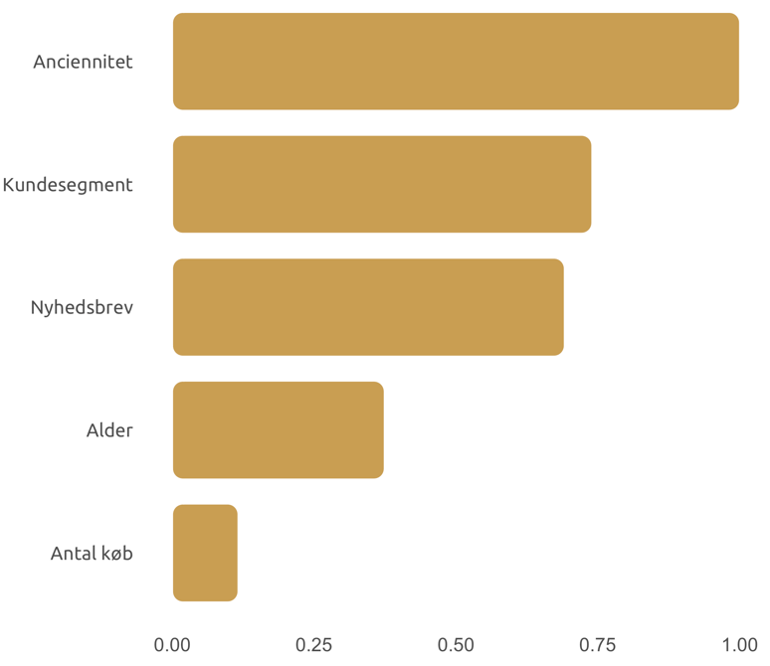
Figure 1 Feature importance.
The graph above shows the most important variables for a model that predicts customer churn in a fictitious company. We can see that the variable 'Tenure' has the highest predictive value for the model, followed by 'Customer Segment' and 'Newsletter'. The values are scaled so that the most important variable receives a value of 1.
If you want to know more - global and local explanations
It is always good to know which variables are most valuable to a model and contribute the most to its predictions. In addition, it often provides even greater value to dig a little deeper and get answers to questions such as "what is the impact of a customer's age on the risk of churn?" or "is the risk higher or lower depending on whether one is male or female?". This type of insight is often called 'global effects' or 'explanations' and can provide the business with answers to their specific hypotheses and contribute to the formulation of data-driven strategies and actions. While the so-called 'feature importances', explained above, provide an overview of the most important data for a model, global explanations show how and in which direction the values of the variables affect the model's predictions.
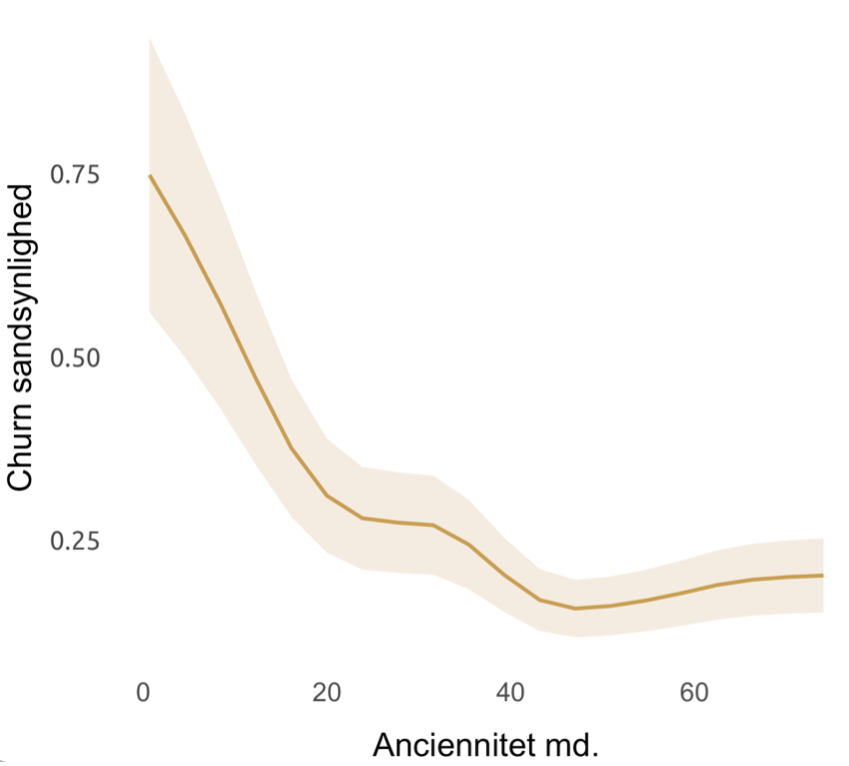
Figure 2 Globale changes.
In this graph, we can see how customers' tenure affects the probability of churn when all other variables are held constant. It is clear that the probability drops significantly in the first few months and then gradually flattens out as tenure increases.
In addition to global effects that illustrate relationships between predictions and values within individual input variables, it is also possible to explain individual predictions and understand which variable values, for example, increase or decrease the probability of churn or sales estimates - that is, local explanations. This knowledge can be used, for example, in retail and subscription businesses to optimize customer interactions so that the right messages can be sent to the right customers based on insights from the model. Another example could be in production and supply industries, where predictive maintenance models are used to predict equipment breakdowns and failures. Local effects can explain why the model predicts a breakdown of a machine or other equipment.
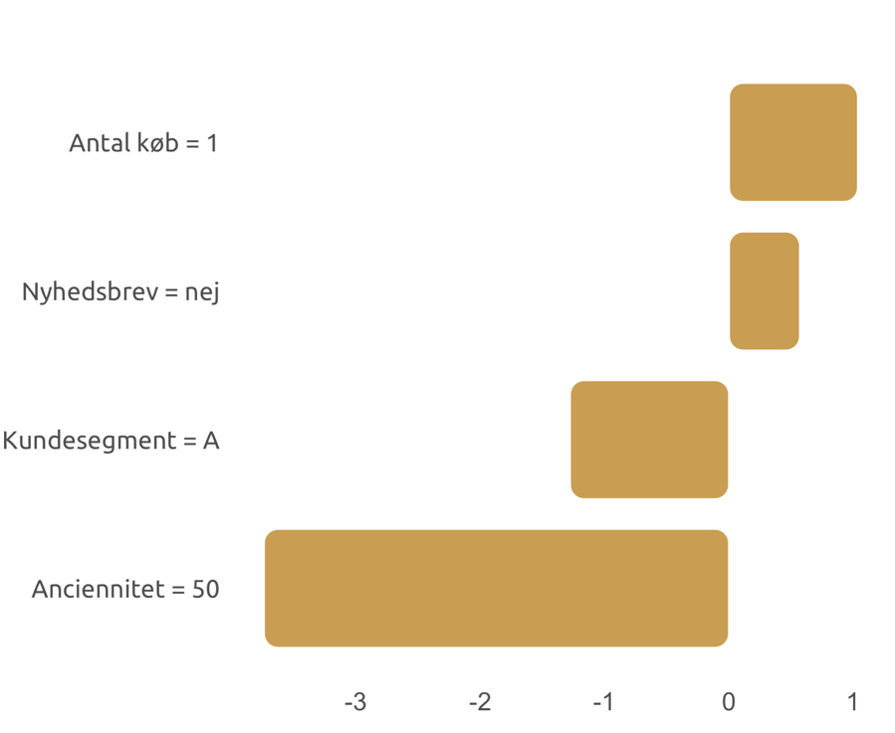
Figure 3 Local explanations.
In the example of a local explanation above, we see how a prediction for a single customer is affected by different information about that customer. We see, among other things, that a low number of purchases "suggests" churn, while the customer's high seniority clearly reduces the likelihood of churn.
Responsibility and ensuring fairness
For companies using AI solutions that affect ordinary people, it is particularly important to prevent discrimination based on factors such as gender or ethnicity. When it is possible to explain how a model works and what it actually does when processing new data, these insights can also be used to ensure that the model makes fair decisions that do not disadvantage certain population groups. In this case, the goal is no longer to achieve the best possible model performance, but rather the best possible performance given that the model is fair. In many cases, however, it will not be sufficient to simply avoid using demographic information such as ethnicity directly when training a model. Such sensitive information can be hidden in other information about an individual. For example, one could imagine that a model for credit assessment that uses geographic data could provide unfair estimates based on ethnicity if there are clear correlations between certain areas and ethnicity.
Examples of industries and use cases where it may be important to consider ensuring fairness in the models:
-
Insurance - claims handling
-
Finance - loans and credit assessment
-
Healthcare - patient complaints and treatment options
Trust is everything for the business
Of course, not all AI solutions need to benefit from explainable AI components. However, in many cases, it is an important element - not just in the understanding of business users, but also in the very trust in the use of AI in important business tasks and decisions in general. If there is no trust, the solution is unlikely to be used to the same extent and will therefore never truly be a success for the business. Users' trust in what the model tells them is therefore a necessity for succeeding with AI projects. It is therefore important that the relevant parts of the business are involved from the start when developing AI solutions. By involving users, among other things, trust can be increased by using their unique knowledge and experience to formulate hypotheses about what could potentially drive a model's decisions. The finished model will subsequently be able to answer the hypotheses and be a great help in the model development phase to avoid errors and unintended biases.
The demand for AI solutions that involve insights created with explainable AI methods will likely only grow in the future, as more and more companies become aware of the opportunities that explainable AI provides. In industries such as healthcare and finance, where decisions affect the lives of ordinary people, there may even be clear requirements that all predictions made by AI/ML models in production should be transparent and explainable in a credible manner.
The purpose of this post was to provide a brief introduction to how the methods are used in the development phase to validate models and data, and to ensure that predictions are fair and made on a correct and responsible basis. Similarly, companies and end-users can benefit greatly from being able to find answers to why the model says what it does. Ultimately, it's about transparency and trust, and that's exactly what's needed to create success with AI and machine learning - especially when these technologies are used to make automated decisions.