
It almost goes without saying that today, deriving insights from data, is more important than ever, not only to gain insights, but it has now become a necessity simply to be able to compete in the complex world we live in. Along with this obviously comes massive amounts of data, data that needs to be procured, stored and analyzed in a fast and efficient manner, and through the years a whole host of products and technologies have become available to support businesses in these challenges, but the landscape is scattered, and services are not always designed to be connected and integrated in an easy way.
Back in 2015, Microsoft noticed this and started the development of a unified platform that would cover the core capabilities required for a modern data platform, without having to provision and configure many different services. So exactly what is Azure Synapse Analytics and what can you use it for? Let’s take a look into the components, features, security and more in the next section.
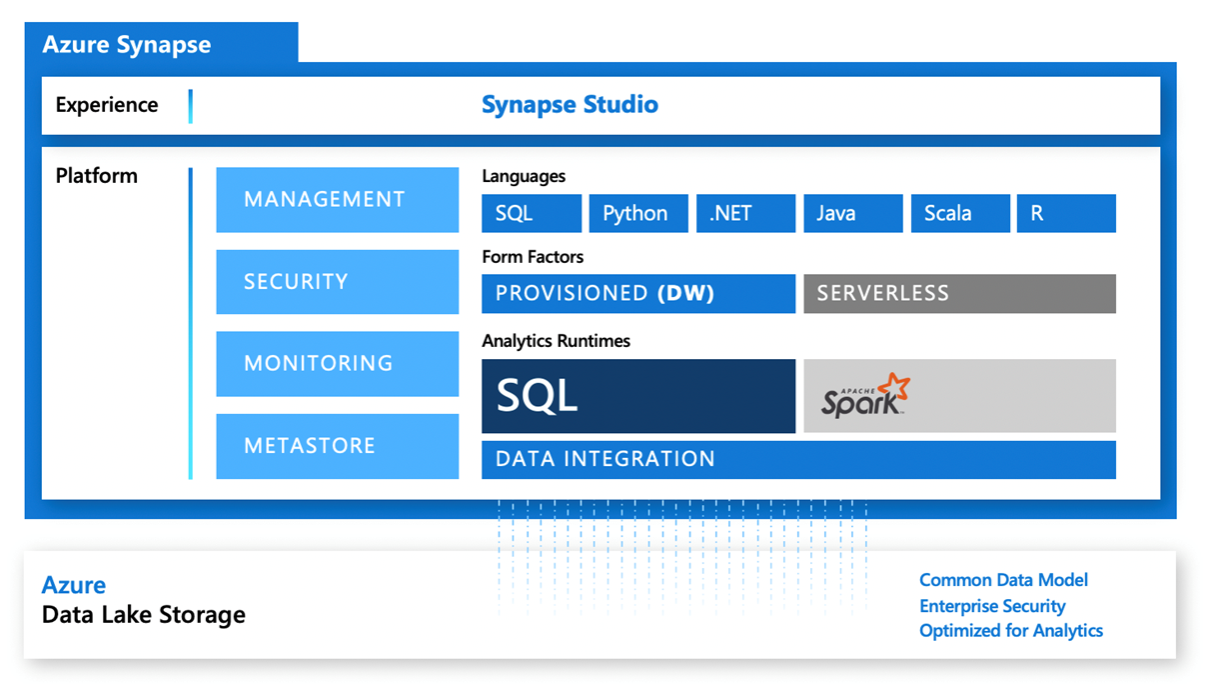
The diagram above depicts all the components contained within Azure Synapse Analytics and is widely used as part of the documentation provided by Microsoft, however it is not immediately clear exactly what’s what, so perhaps a better way to look at the included components is to split them into their main area; storage, compute, orchestration and the development environment surrounding these components.
Storage
The main storage for Azure Synapse Analytics is Azure data lake storage which is used to store file-based data as well as the metadata store required for Synapse. You would use the data lake when you have very big data volumes or have to deal with semi-structured data. It even has support for the storing of data using the Common Data Model metadata system, allowing the data to be easily shared across applications and business processes such as Power Apps, Power BI and Dynamics 365.
File-based storage is however not the only option within Azure Synapse Analytics as data is stored relationally when using SQL Pools, which we will discuss later in this article.
Apart from the built-in storage options, Azure Synapse Analytics also has the ability to connect/use Spark tables and, through the use of Azure Synapse Link, it can connect to Cosmos DB.
Compute / runtimes
There are three main compute options within Azure Synapse Analytics, two running a somewhat familiar flavor of SQL and one using Spark, which allows for a number of different languages such as Python, SQL and Scala etc.
Serverless SQL pool
SQL Serverless is an on-demand SQL pool already set up for you when setting up a Synapse workspace and allows you to write T-SQL queries over files stored in the aforementioned data lake. It can be used for discovery and data exploration, such as ad-hoc queries that analyze the contents of those files, aggregations, counts and so on. Another scenario is to use SQL Serverless to transform data in the data lake, for instance converting CSV files to parquet or picking up data for modelling and storing it back into the data lake.
As the name suggests this service is serverless, meaning no infrastructure is required and you pay only for the query execution in a price-per-terabyte pricing model. Most T-SQL functions are supported, and it supports queries against files in various formats such as Parquet, CSV and JSON.
Dedicated SQL pool
Dedicated SQL pools are a provisioned option within Synapse and are ideal for data warehouse scenarios when dealing with big amounts of data and complex modelling. You specify exactly how many compute nodes you would like; how big they should be and so on. You can then turn on the SQL pool when needed and either scale down or completely turn it off when you do not need it anymore. You pay by the hour as long as the SQL Pool is turned on, no matter how much you use it, the compute is provisioned and ready to go.
It is an MPP architecture built on the foundation of SQL Server, and like other MPP type architectures, it separates storage and computes, and in the case of Synapse, compute is determined by an arbitrary unit of computing power called data warehouse units (DWU). It is not a new technology, but rather an evolution of the previously named “Azure SQL Data Warehouse” and before this, it can be traced back to the “SQL Server Parallel Data Warehouse” offering. With the introduction to the Synapse platform, Microsoft has introduced a few new enhancements, such as being able to run machine learning predictions directly in T-SQL using the PREDICT function together with a model in the “onnx” format and the new COPY statement which promises vastly increased performance compared to the previous Polybase option.
Compared to other similar services such as Snowflake, Google BigQuery and Amazon Redshift, SQL Pools within Azure Synapse Analytics, does provide a very attractive offer in terms of price vs. performance. GigaOm publishes an annual benchmark performance test report comparing big data analytics platforms and in the recently announced report, Synapse came in second. Read the report here.
Apache Spark pool
Apache Spark pools inside Azure Synapse Analytics can be used in data- engineering & preparation scenarios as well as for machine learning and once running you can interact with it through Azure Notebooks using either SQL, Python, C#, Java, R or Scala, and even a mixture of languages within the same notebook. It is important to note that this is not to be confused with Databricks as they use their own adaptation of Spark with addons, whereas this version is specific to Microsoft.
When setting up a provisioned Spark pool you set up a cluster where you specify how many compute nodes you would like, the node size in terms of processors and memory. In addition, you need to specify which version of Apache Spark you would like, along with packages you would like to have available on the cluster. Choosing a Spark version is however quite easy at the moment, only 2.4 is supported but more are sure to come later.
Similar to the SQL Pool, Spark pools are paid by the hour and the cluster can be configured to auto-pause, so after a set limit of idle time, the cluster will pause, and you will no longer be charged. Once attached to a notebook it will automatically spin up and be ready to use.
Orchestration
For orchestration, Azure Synapse Analytics uses an adaption of the already familiar Azure Data Factory, but in here it is named Synapse Pipelines. Features and components from Azure Data Factory are almost the same and eventually, it will be the same thing. Along with this also comes the feature of Mapping Data Flows which underneath uses a Spark cluster to perform the data modelling that you build in your data flows.
With General Availability also came support for Git integration which was native to Azure Data Factory but was missing from Azure Synapse Analytics while in preview.
Development enviroment
The final big component of Azure Synapse Analytics is Synapse Studio, which is the in-browser based “frontend”, which is the main development- and access point for everything you do in Synapse. It consists of a number of “activity hubs”:
Overview
The overview hub is the main landing page when opening Synapse Studio with links to recently used files, pinned scripts, useful links and documentation as well as links to the other hubs which you can use depending on what your role is and what you would like to do. From this you can easily create a new SQL script, notebook or a Power BI report just to name a few.
Data
The data hub provides an overview of all the storage accounts and databases you have in Synapse. You can browse storage accounts, open and preview data in files, organize folders or even create SQL or Pyspark snippets already connected to the data so you are ready to work with it straight away. Databases and objects can also be searched and previewed inside of the datahub.
Manage
In the manage hub you have one entry point to configuring the Synapse workspace. Provisioned resources such as SQL pools and Spark pools can be turned on and off and scaled to a different size etc. It is also in the manage hub where you create linked services & integration runtimes to services and systems external to Synapse, as well as the configuration of triggers for pipelines. Finally, this is also where you configure access to the Synapse workspace and storage options.
Develop
You use the Develop hub to build and execute scripts and dataflows. From here you can author and execute SQL scripts on provisioned SQL pools or SQL serverless, view results both in table and chart form and finally export datasets to CSV, Excel, JSON or XML.
Monitor
The monitor hub is where you monitor all the activities within your Synapse workspace. You can monitor currently running activities as well as historical activities for queries and pipelines from Apache Spark and SQL.
Orchestrate
The orchestrate hub is where you build and design pipelines for moving and transforming data. The experience is almost identical to Azure Data Factory, but objects like linked services and integration runtimes have been moved to the management hub.
What have we learned?
From the brief walkthrough of the components above, it is clear that Azure Synapse Analytics is not just one service but rather a combination of services and technologies wrapped within the same workspace experience.
It allows for multiples sources of data, both unstructured or structure and regardless of where it resides, to be brought to the same platform. From there, all types of data professionals in the business can seamlessly and securely collaborate, share and analyze data.
It supports multiple languages so no matter whether you prefer Python, Scala or are more familiar with SQL there is a great opportunity to make great use of existing skills across the business. If you’re curious about whether Azure Synapse Analytics is right for your business we’ll be happy to help. Contact us here.