
AI (Artificial intelligence) and machine learning can solve an enormous number of problems – and contribute to a better and more efficient society through smarter and optimal workflows.
It is essential that we develop and harness the potential of AI in an ethically responsible manner.
The purpose for which one develops their AI system has a significant impact on the approach to developing AI responsibly. Ethically, you must always consider whether it is a use you are interested in developing. This may include weapon systems or manipulating the population through internet advertising.
However, it is not always necessary to do a major ethical analysis of one's AI model. For example, if one develops a system that takes pictures of a conveyor belt to sort defective products or bad apples, or a system that optimizes the sequence of trees to be felled in forestry, it is not as relevant to investigate whether one's model has been ethically and responsibly developed. Where one should consider responsible AI is when using personal sensitive data, or if one's AI system has an impact on people. It can be systems that use biometric data such as facial recognition or systems that approve applications for insurance or bank loans.
Responsible AI can be viewed from several angles, but we have chosen to focus on three topics that cover the most important elements and most significant challenges:
- Explainable AI
- Fairness
-
Security and robustness
Explainable AI
With explainable AI, one moves away from the often-discussed "black-box" approach to machine learning, where it is borderline impossible to know what is actually happening in the algorithm. With explainable algorithms, one can intuitively understand and explain why the model is doing what it is doing, which offers many advantages. It creates increased credibility of the results, and furthermore, one can utilize the knowledge of how different variables and factors affect the result. For example, if you know exactly how a variable like 'age' affects the prediction of the risk of canceling a subscription, you can use this knowledge to make targeted interventions where it has the greatest effect. This can be beneficial for a marketing department, for instance. One can also use this knowledge to extract information about the relationship between one's data and the real world, from where the data originates, as the model can explain and demonstrate complex relationships. We have written much more about explainable AI here.
Fairness
The concept of fairness refers to treating everyone equally. With fairness, we want to avoid our algorithm discriminating on age, gender, ethnicity, or other demographic characteristics. If demographic information is included in the data, there is a risk that the model will discriminate against population groups, but even if sensitive demographic data is not included in the training of the model, the model can still find connections between other features that can lead to discrimination. Therefore, it is not enough to simply exclude sensitive information such as race, gender, or religion from the dataset. If the AI model has an impact on individuals or groups' lives, there is a need to look into the model's fairness.
To examine fairness and attempt to mitigate any unfairness in our model, we first need to define what we mean by fairness.
This consists of two subtasks:
- What do we measure fairness on? Is it age, religion, gender, a combination - or something else entirely?
- How do we measure unfairness? Do we require the same sensitivity when it comes to finding positive examples, such as bad payers, as when it comes to finding negative examples?
An example could be the following result from a machine learning model that determines whether the person can be approved for the requested loan.
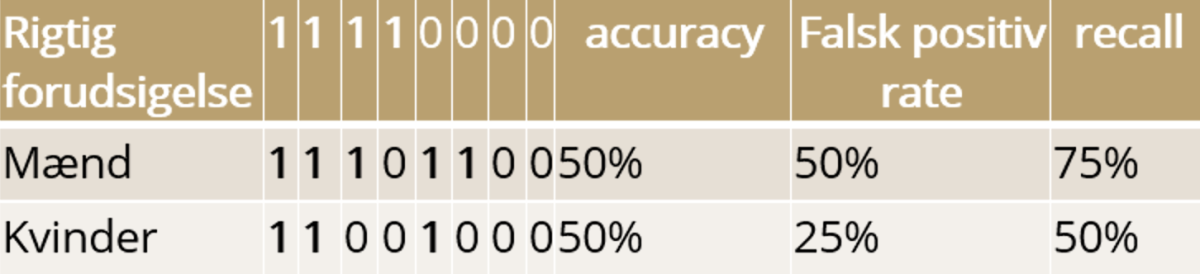
In this case, the model has an accuracy of 50% for both men and women, so if we only look at the accuracy, there is no unfairness in the model. False positive rate tells us how many people have been approved for a loan when they shouldn't have been, and recall describes how many people the model approves out of all who should be approved. However, looking at the false positive rate, it is clear that the model is not completely fair. In the example, women are discriminated against by both receiving fewer rightful loan approvals and at the same time having a lower amount of wrongful loan approvals than men.
So we see that fairness cannot be defined in a general way, but the definition depends on the nature of the problem and how the solution is to be used.
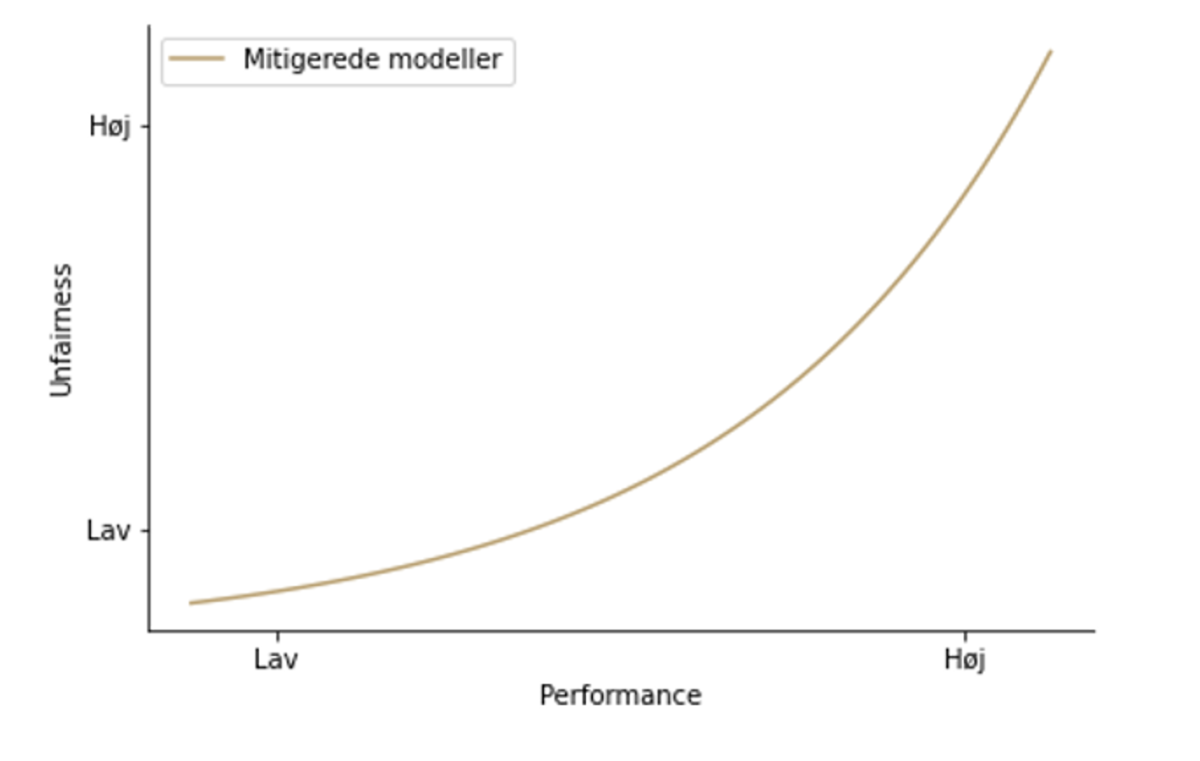
If in the analysis, one discovers that their model discriminates against certain groups, unfairness can be mitigated. This is done by weighting the different groups differently in the training, so that the discriminated group gets a higher weight/importance in the model's training. This leads to a decrease in the performance of the model, and therefore one must decide where the balance between fairness and performance lies in the specific case.
As can be seen in the plot below, one would have to choose a model along a curve that provides a compromise between performance and fairness.
Security and robustness
Security is a broad concept that covers many things. When AI systems are used in the real world, they also have an impact on it. Since AI systems are not perfect, a security consideration to take is to map out and analyze the impact that incorrect predictions can have. This varies depending on the use case. An error in a translation system is very different from a potentially catastrophic error in a system for a self-driving car or a system in the healthcare sector.
Since AI models are based on data, it is also important to secure data so that unauthorized individuals cannot exploit access to it. If an unauthorized person has access to data, there is a risk that others will gain access to sensitive personal information.
Another risk is that an unauthorized person changes the data, so that the model makes incorrect predictions after the next training. This means that others may have an influence on the model - and thus the conclusions drawn based on it.
In addition to normal security, you can secure the model and data by limiting access for outsiders to the model and its predictions. It is also possible to protect sensitive data using so-called differential privacy, where noise is added to the dataset so that the original data points cannot be traced. There are several advanced ways to protect data using, for example, homomorphic encryption, where calculations can be performed directly on encrypted data. However, this is computationally very heavy and has significant limitations on the type of calculations that can be performed.
A final security consideration concerns robustness. To use AI responsibly, it is important to know that it continues to behave as expected in a production environment. In Kapacity, we have developed an MLOps framework in the Microsoft Azure cloud platform that can track and keep track of versions of data and models so that changes can be detected and analyzed for each new model. Detection of data drift - when the data underlying the model changes significantly - is also included, allowing for automatic retraining when new data is available. By monitoring the models and the data they are based on, one can ensure high operational security and robustness.
Summary
Responsibility in AI is a broad and complex topic that includes many sub-elements that are more or less relevant depending on the specific problem. However, it is generally important for any project to consider whether the project is at risk of being irresponsible in terms of explainability, fairness, or security.